在开始之前,明确几个概念:
HTTP 即 “超文本传输层协议”
协议是指计算机之间通信的规则的集合,这些规则是**约定俗称**的。
超文本,HTML,是http设置之初的传输目标
本文将会以HTTP的历史为主线,讲述不同版本之间的差异,以及不同版本的新特性。
概述
HTTP分为三个版本:HTTP/0.9,HTTP/1.0、HTTP/1.1、HTTP/2.0,HTTP/3.0
HTTP/0.9
HTTP/0.9是HTTP的第一个版本,它是一个极简的协议
只有一个命令GET,没有HEADER等描述数据的信息,服务器发送完毕数据之后就关闭TCP连接。
他的报文只有一行,如下:
1 | GET /index.html |
HTTP/1.0
- 随着每个请求发送协议版本信息,原来第一行只有 方法+路径,现在变成了 方法+路径+协议版本
- 服务端会发送状态码,使客户端可以更灵活的处理请求
- 新增了一些请求方法,POST、HEAD
- 引入了HTTP Header,具备了传输纯文本HTML以外的能力
以下是HTTP/1.0的报文格式:
1 | GET /mypage.html HTTP/1.0 |
Content-Type 示例
1 | Content-Type: text/gif |
- User-Agent: 告诉服务器客户端的类型和版本信息,服务端可以因此返回不同的资源,可以用于解决浏览器兼容性问题
- Server:用于告诉客户端服务器的类型和版本信息
- Content-Type: 用于告诉客户端返回的资源类型,如果存在,浏览器将不考虑文件类型完全按照这个字段解析,如果不存在,则由浏览器自主判断
- Body: 服务器返回的资源
HTTP/1.1
HTTP/1.0是HTTP的第一个正式版本,它的特点是:
- 连接可以复用,节省了多次打开TCP连接的时间
- 增加管线化技术,实现流水线、并发两种请求方式
- 增加了PUT、DELETE、TRACE、OPTIONS等方法
- 增加了状态码
- 引入内容协商机制,客户端和服务器交换最合适的内容
1 | GET /zh-CN/docs/Glossary/CORS-safelisted_request_header HTTP/1.1 |
可以看到,新增加了几个字段
- Accept: 告诉服务器客户端接受的资源类型
- Accept-Language: 告诉服务器客户端接受的语言
- Accept-Encoding: 告诉服务器客户端接受的编码方式
- Referer: 告诉服务器客户端请求的来源,允许服务器生成回退链接,用于日志记录等,但是可能会带来隐私问题,Referrer-Policy可以控制这个字段的发送
- Content-Encoding: 告诉客户端返回的资源的编码方式
- Etag: 用于缓存控制
- Last-Modified: 用于缓存控制
- Transfer-Encoding: chunked,告诉客户端返回的资源是分块传输的
- Vary: Cookie, Accept-Encoding,告诉客户端服务器根据这两个字段来生成缓存
- Connection: Keep-Alive,告诉服务器客户端是否支持长连接,即保持TCP连接
- Keep-Alive: timeout=5, max=1000,告诉客户端服务器保持连接的时间和最大连接数
- Server: Apache,告诉客户端服务器的类型和版本信息
特性
在这个版本里,增加了许多字段,这些字段可以让客户端和服务器更好的交互,提高了HTTP的性能
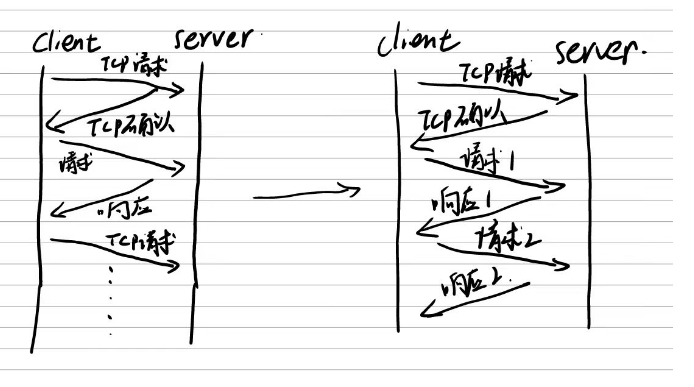
TCP连接复用
相关字段:
- Connection: Keep-Alive,告诉服务器客户端是否支持长连接,即保持TCP连接
- Keep-Alive: timeout=5, max=1000,告诉客户端服务器保持连接的时间和最大连接数
在HTTP1.0以及其以前,发送一个HTTP请求需要建立一个TCP连接,信息发送之后,立即关闭连接,这样的方式效率很低,因为TCP连接的建立和关闭都需要时间,
而且每次建立连接都需要三次握手。
所以HTTP1.1引入了长连接,即在一个TCP连接上可以发送多个HTTP请求,这样就可以节省大量的时间。
HTTP缓存
强缓存

浏览器不会向服务器发送请求,直接从缓存中读取资源
- Expires: Tue, 19 Jul 2016 00:59:33 GMT
- Cache-Control: max-age=3600
在HTTP 1.0时,使用是Expires字段,告诉客户端资源的过期时间
但是时间格式难以解析,也发现了很多实现的错误,有可能通过故意偏移系统时钟来诱发问题
在HTTP 1.1时,引入了Cache-Control字段,可以更加灵活的控制缓存策略,如max-age=3600,表示资源在3600秒内有效
上文提到,直接从缓存中读取资源,这里的缓存是指浏览器的缓存
初次请求时,浏览器会将资源缓存到本地,下次请求时,浏览器会判断是否有**名称相同**的资源,如果有,直接从本地读取,不会向服务器发送请求
比如第一次请求一个index.html,浏览器会将这个资源缓存到本地,下次请求时,浏览器会判断是否有index.html这个资源,如果有,直接从本地读取
拓展:
为什么在本地开发原生html的时候需要保存一下才能显示最新的界面?
因为浏览器会缓存html页面,保存一下是为了更改html资源的hash值,这样才能显示最新的界面
协商缓存
两种方法
- Etag + If-None-Match
- 第一次请求时,设置Etag
- 第二次请求时,随If-None-Match字段发送Etag,服务器根据Etag判断资源是否更新,如果没有更新,返回304,否则返回200
- Last-Modified + If-Modified-Since
- 第一次请求时,设置Last-Modified
- 第二次请求时,随If-Modified-Since字段发送Last-Modified,服务器根据Last-Modified判断资源是否更新,如果没有更新,返回304,否则返回200
HTTP/2.0
特点:
- 由原来的文本协议变成了二进制协议,即,不在可读
- 多路复用,一个TCP连接上可以同时发送多个请求
- 首部压缩,减少了首部的大小
HTTPS
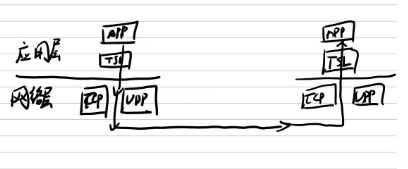
HTTPS是HTTP的安全版本,它是在HTTP的基础上加入了SSL或者TLS协议,用于加密数据传输
SSL是TSL的前身
TSL加密过程
- 客户端向服务器发送一个请求,请求建立一个安全连接,同时发送TSL版本,以及生成并发送第一个随机数 (此时,客户端拥有第一随机数,服务端拥有第一随机数)
- 服务端收到请求,向客户端发送一个证书,证书中包含了服务端的公钥,以及生成并发送第二个随机数
(客户端拥有公钥、第一随机数,第二随机数,服务端拥有公钥、私钥、第一随机数,第二随机数)
客户端生成一个预主密钥,并使用公钥加密,之后发送到服务端,服务端用私钥解密(此时,客户端拥有公钥、第一随机数,第二随机数、预主密钥,服务端拥有公钥、私钥、第一随机数,第二随机数,预主密钥)
- 之后,服务端和客户端分别用第一随机数、第二随机数、预主密钥计算出会话密钥
- 之后,开始通信
这样具体在哪些方面比较安全?
- 信息是加密的,即人类无法阅读
- 客户端全程不接触用来解密的私钥,防止了客户端离谱的操作带来的问题
- 会话密钥生成过程中完全没有经过网络传输
公钥私钥加密解密示例
- 公钥 (17, 3233) 私钥 (275, 3233)
- 加密过程
- 明文 72
- 密文 72^17 % 3233 = 2201
- 解密过程
- 密文 2201
- 明文 2201^275 % 3233 = 72
注意:
- 这只是一个简单的示例,攻击者可以通过密文、公钥爆破解出原来的明文。但是!
由于爆破过程中可以产生多个结果,所以,爆破者无法确定哪个是正确的明文!再但是,由于计算机的计算能力,爆破者可以通过多次尝试,找到正确的明文 - 为了防止这种情况,真实的情况可以通过增加密文长度,增加公钥私钥长度,增加计算量,来增加破解难度
- 比如RSA加密